
Introduction
The latest instruction-tuned models are here, available in three versions: 8B, 70B, and 405B. These models are some of the best open-weight models available today. The largest, the 405B model, is particularly impressive, even surpassing many closed-weight models. In this article, we’ll explore the capabilities of these models, how they compare to others, and how you can run them on your local machine. We’ll also discuss the new agent system from Llama, an open letter from Mark Zuckerberg, and the potential for a multimodal Llama. Let’s dive in!
Table of Contents
- Technical Details
- Model Architecture and Training
- Running the Models Locally
- Comparing with Other Models
- Best Use Cases
- Multimodal Capabilities
- Llama Agentic System
- Open Source AI: An Open Letter from Mark Zuckerberg
- Conclusion
Technical Details
The new instruction-tuned models boast a huge context window. The previous versions had a context window of only 8,000 tokens. Now, it has been extended to 128,000 tokens, making it comparable to the context window of GPT-4 models. This improvement makes the models significantly more useful.
Enhanced Training Data
The quality of training data is crucial. Compared to the previous Llama models, the new models have enhanced pre-processing and curation pipelines for pre-training data, as well as improved quality assurance and filtering methods for post-training data. This focus on training data quality is a key reason behind the performance improvements.
Model Architecture and Training
The architecture of these models remains similar to the older versions. One of the highlighted use cases for the larger 405B model is synthetic data generation for fine-tuning smaller models. The scale of data involved is impressive: the pre-training data comprises about 16 trillion tokens, and it was trained over a cluster of 16,000 H100 GPUs.
Efficient Inference
To support large-scale production inference for the 405B model, it has been quantized from 16 bits to 8 bits. This reduces computational requirements and enables the model to run on a single server node.
Running the Models Locally
Running these models locally requires significant resources, especially for the 405B model. Here’s what you need:
- 8 billion model: 16 GB of VRAM (16-bit precision)
- 70 billion model: 140 GB of VRAM
- 405 billion model: 810 GB of VRAM (16-bit precision)
For the 405B model, using 8-bit precision reduces the VRAM requirement to 405 GB. If you want to run it in 4-bit precision, you would only need around 203 GB of VRAM.
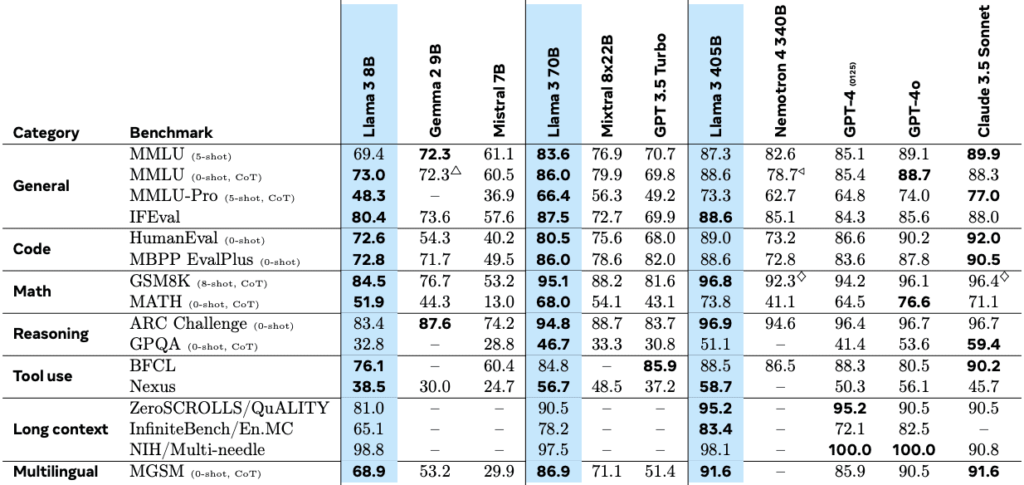
Comparing with Other Models
These models are highly competitive with the best in the industry. The 405B model, for example, is comparable to larger models like GPT-4 or GPT-4 Turbo. The smaller models (8B and 70B) are distilled versions of the 405B, making them highly efficient and effective for various tasks.
Benchmarks
On benchmarks, the 405B model performs exceptionally well. It is comparable to other leading models like Open GPT-4 Turbo and Anthropic’s Opus model. In terms of math problem-solving skills, it is just behind GPT-4 but better than 3.5 Sonet.
Best Use Cases
The best use cases for the 405B model include synthetic data generation and knowledge distillation for smaller models. The 8B and 70B models can also serve as judges, a popular use case for larger models like GPT-4. Additionally, these models can generate domain-specific fine-tunes and support multilingual applications.
Multimodal Capabilities
These models are multimodal, meaning they can process images, videos, and speech as inputs and generate these modalities as outputs. This capability is highlighted in their technical report, although the multimodal version has not yet been released.
Supported Languages
The models are now multilingual, supporting languages like Spanish, Portuguese, Italian, German, Thai, and more. This is great news for non-English speakers.
Llama Agentic System
With this release, Meta is introducing the Llama Agentic System, an overall system that can orchestrate several components, including calling external tools. This system is designed to provide developers with the flexibility to create custom offerings that align with their vision.
Llama Guard 3 and Prompt Guard
Along with the agentic system, they are also releasing Llama Guard 3, a multilingual safety model, and Prompt Guard, a prompt injection filter.
Open Source AI: An Open Letter from Mark Zuckerberg
Mark Zuckerberg has written an open letter titled “Open Source AI is the Path Forward,” advocating for open-source AI systems. He highlights the importance of:
- Training, fine-tuning, and distilling our own models
- Controlling our own destiny and avoiding vendor lock-in
- Protecting data privacy
- Ensuring models are efficient and affordable to run
- Investing in ecosystems that will be standards for the long term
Conclusion
The latest instruction-tuned models from Meta are powerful, versatile, and efficient. Whether you’re interested in running these models locally, using them for synthetic data generation, or exploring their multimodal capabilities, there’s a lot to look forward to. With the introduction of the Llama Agentic System and updates to the models’ licenses, Meta is setting a new standard in the AI industry. Keep an eye out for further developments and start exploring the potential of these cutting-edge models.
Leave a Reply