
Imagine your AI agent not just following a single instruction but juggling tools, memory, human feedback, and external data, all without breaking a sweat. That level of sophistication comes from mastering Context Engineering. Think of it as designing the brain and nervous system behind your agent, rather than just handing it a single prompt and hoping for the best. In this post, we’ll unpack what context engineering really means, how it goes beyond prompt engineering and Retrieval-Augmented Generation (RAG), and why it’s the key to creating reliable, error-resistant AI agents.
Table of Contents
- What Is Context Engineering?
- Prompt Engineering vs. Context Engineering vs. RAG
- Why Context Engineering Is a Superset of Prompt Engineering
- Transforming LLMs into Autonomous Agents
- Managing Context Windows & Token Limits
1. What Is Context Engineering?
Context Engineering is the discipline of designing a dynamic system that feeds an LLM everything it needs to solve a task (tools, data, memory, formatting rules etc.) rather than just a one-line instruction. It’s about assembling and orchestrating all the moving parts so your AI agent can operate autonomously and reliably.
2. Prompt Engineering vs. Context Engineering vs. RAG
- Prompt Engineering: Crafting the instruction you send to the LLM. e.g., “You are an expert chef. Given these ingredients, design a three-course meal.” That’s one shot.
- Retrieval-Augmented Generation (RAG): Dynamically pulling in external documents or database snippets at runtime to enrich the LLM’s context.
- Context Engineering: Puts it all together. You design the full pipeline; when to call RAG, how to format retrieved chunks, which tools to invoke (calculator, API, etc.), and how to maintain memory across turns.
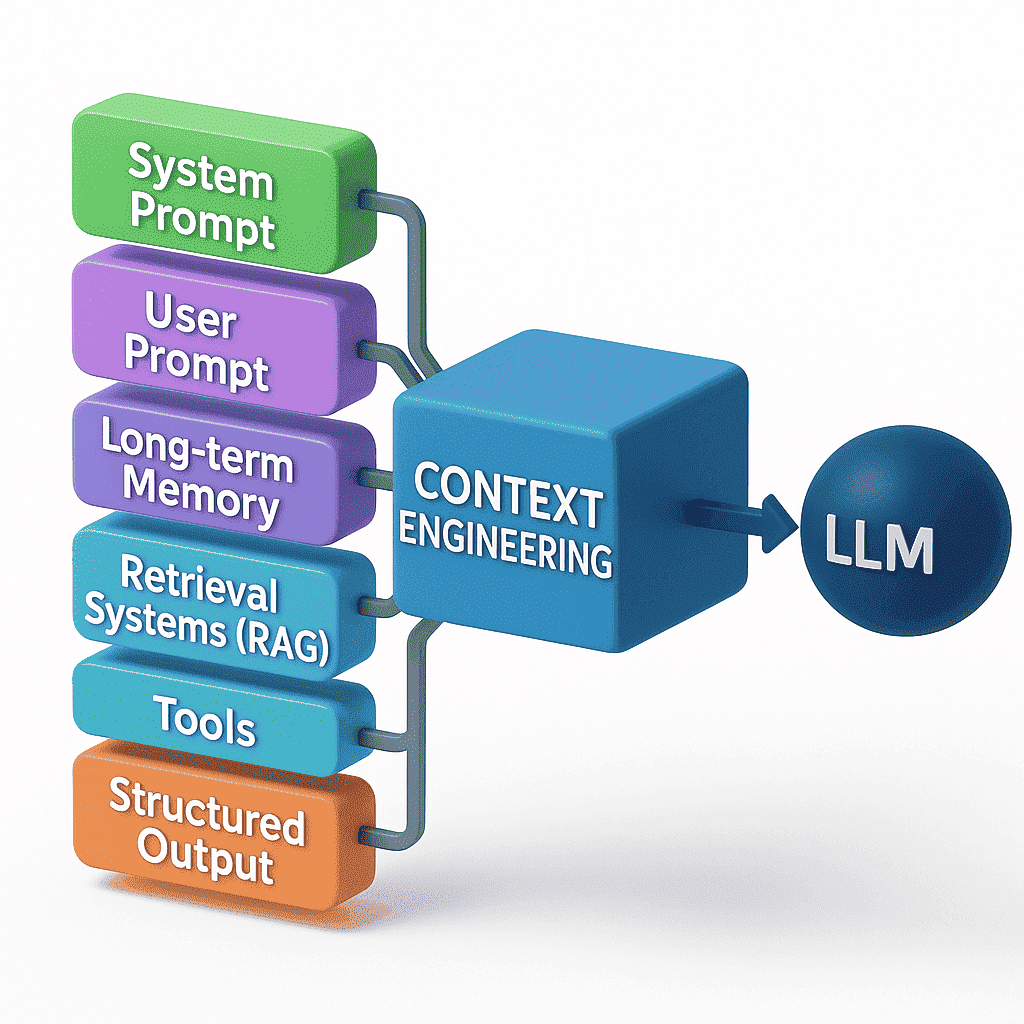
3. Why Context Engineering Is a Superset of Prompt Engineering
- Beyond Single Prompts: Your initial prompt becomes just one component in a larger system.
- Workflow Design: You define decision points (“if user asks X, call tool Y”), memory storage, error handling, and fallback strategies.
- Scalability: Instead of hard-coding new prompts for every edge case, you update the context pipeline to integrate new data sources or tools.
4. Transforming LLMs into Autonomous Agents
Context engineering is what elevates an LLM from a chatbot to the brain of a self-driving agent. By carefully orchestrating tool use, memory retrieval, and human checks, you build a system that can plan, execute, and adapt like a virtual assistant that can schedule meetings, process data, and even troubleshoot its own mistakes.
5. Managing Context Windows & Token Limits
- Token Budgets: LLMs have hard caps on how many tokens they can ingest (e.g., 8K, 32K tokens).
- Relevance Ranking: A context engineer decides which info is mission-critical and which can be compressed, summarized, or dropped.
- Chunking Strategies: Break long documents into smaller, linked segments. Load only the segments relevant to the user’s current query.
Summary
Context Engineering shifts your view from “write one perfect prompt” to “design a flexible system.” It unites prompt crafting, RAG, tool orchestration, memory management, and error handling into a cohesive pipeline. Mastering this discipline is what turns today’s chatbots into tomorrow’s powerful, autonomous AI agents.
FAQ
- Is context engineering just a fancy name for prompt engineering?
No, prompt engineering is one slice of the pie. Context engineering includes data retrieval, tool calls, memory state, and pipeline logic. - When should I use RAG vs. context engineering?
Use RAG for pulling in external docs on demand. Use context engineering to embed RAG into a larger workflow so the agent knows when and how to invoke it. - Do I need special libraries for context engineering?
Frameworks like LangChain or LangGraph help, but you can build your own system with plain API calls, a database for memory, and a lightweight orchestration layer.
Thanks for your time! Support us by sharing this article and exploring more AI videos on our YouTube channel – Simplify AI.
Leave a Reply